WinToolkit Pro è un'applicazione desktop avanzata scritta in C# (WPF) progettata per semplificare la manutenzione del sistema, il backup e la gestione dei software su Windows. Nata come estensione del progetto Angolo di Windows, offre un'interfaccia grafica moderna e pulita per eseguire operazioni complesse da riga di comando senza dover mai aprire il terminale.
41
Indice dei Contenuti
L’intelligenza artificiale sta rivoluzionando il nostro modo di interagire con la tecnologia, ma fino ad ora gran parte del suo potere è stato concentrato nei data center delle grandi aziende. Negli ultimi mesi, un nuovo trend sta emergendo: l’esecuzione di modelli di AI direttamente sui nostri dispositivi, offrendo maggiore controllo, privacy e, potenzialmente, costi inferiori.
Inoltre OpenAI ha da poco rilasciato il suo modello gpt gratis e accessibile a tutti. Ma cosa significa realmente “AI in locale” e come possiamo iniziare a sfruttarla? In questo articolo ti guiderò passo passo nell’installazione della tua IA locale.
Cosa Significa “IA in Locale”?
Tradizionalmente, quando interagiamo con un’IA come ChatGPT, le nostre richieste vengono inviate a server remoti gestiti da aziende come OpenAI, Microsoft o Meta. L’IA elabora la richiesta e ci invia la risposta. L’IA in locale, invece, significa scaricare il modello di IA sul tuo computer e far funzionare l’IA direttamente lì. Questo ti offre maggiore controllo, privacy e sicurezza delle informazioni che vai a lavorare perché tutto rimane in locale.
I Mattoni dell’IA: Token e Parametri
Prima di addentrarci nei modelli, capiamo due concetti chiave: i token e i parametri. Immagina che l’IA non legga le parole come noi. Invece, le divide in unità più piccole chiamate token. Un token può essere una parola intera, una parte di una parola o persino un segno di punteggiatura.
Quando interagisci con un’IA, il tuo input viene trasformato in token e l’IA genera una sequenza di token per la sua risposta. Il numero di token che un modello può elaborare è una limitazione importante. I modelli di AI “imparano” leggendo enormi quantità di testo, analizzando le relazioni tra questi token.
Mentre i parametri sono come le “connessioni” neurali all’interno del modello di IA. Più parametri ha un modello, più “grande” e potenzialmente più potente è. Un modello con molti parametri può memorizzare più informazioni e generare risposte più complesse. Tuttavia, un modello più grande richiede anche più risorse computazionali (potenza di calcolo e memoria) per funzionare.
Vantaggi e Svantaggi
L’esecuzione di modelli di AI localmente offre numerosi vantaggi:
Privacy: I tuoi dati rimangono sul tuo computer, non vengono inviati a server esterni e non vengono usati per allenare altri modelli.
Controllo: Hai pieno controllo sui dati e sul modo in cui l’IA viene utilizzata.
Costo: Eviti i costi di abbonamento ai servizi di IA basati su cloud.
Ma al tempo stesso hanno diversi svantaggi:
Requisiti Hardware: Eseguire modelli di IA complessi richiede un computer potente, con molta RAM e una buona scheda grafica. . Non tutti i computer sono in grado di gestire questi requisiti.
Complessità Tecnica: La configurazione e la gestione di modelli di IA in locale possono essere complesse, richiedendo una certa familiarità con la riga di comando e la configurazione del software (anche se nel prossimo paragrafo ti mostro passo passo come installarla in modo semplice e chiaro)
Performance: Anche con un hardware potente, le prestazioni dei modelli in locale possono essere inferiori rispetto a quelle dei server cloud, che hanno accesso a risorse computazionali enormi.
Aggiornamenti e Manutenzione: I modelli di IA vengono costantemente aggiornati. Mantenere un modello aggiornato in locale può richiedere uno sforzo considerevole.
Data delle Informazioni: È importante ricordare che i modelli di IA vengono addestrati su enormi quantità di dati. Questi dati hanno una data di scadenza. L’IA potrebbe non essere a conoscenza di eventi o informazioni recenti. Questo è un limite intrinseco a qualsiasi modello di IA, ma è particolarmente evidente quando si utilizza un modello in locale, dove non si beneficia degli aggiornamenti continui che avvengono sui server cloud.
Come installare un modello AI in locale
Ora siamo arrivati al punto cruciale in cui parliamo di come scaricare e installare un modello AI in locale.
Scelta del modello
Diversi modelli di IA si stanno facendo strada verso l’esecuzione in locale. Alcuni esempi includono:
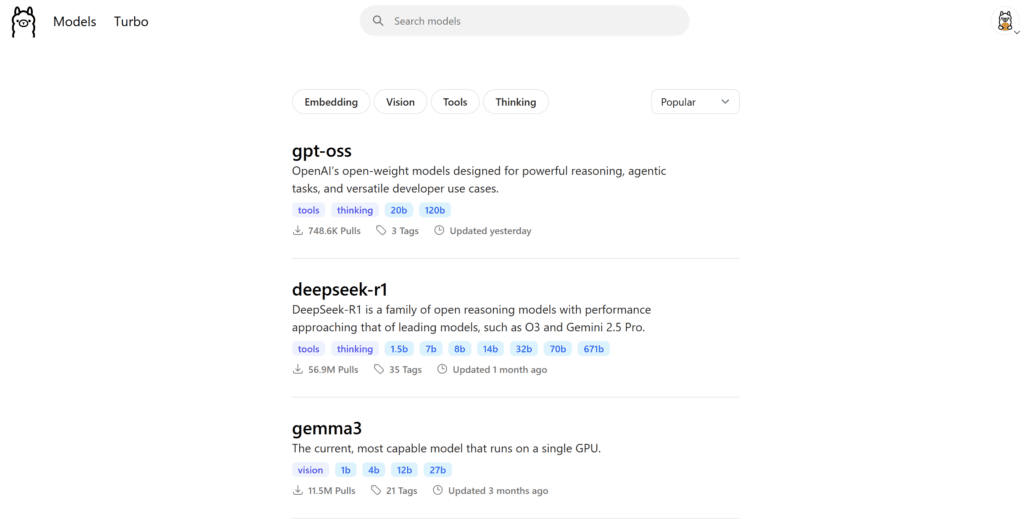
GPTO – OSS (OpenAI): il modello open-source di OpenAI che offre un ottima precisione e potenza di calcolo
Llama 2 (Meta): Uno dei modelli open-source più popolari, disponibile in diverse dimensioni (7B, 13B, 70B parametri) offrendo un buon compromesso tra prestazioni e requisiti di hardware.
Mistral AI: Una serie di modelli open-source che si distinguono per l’efficienza e le prestazioni, particolarmente adatti per hardware meno potente.
Phi-2 (Microsoft): Un modello relativamente piccolo (solo 2.7 miliardi di parametri), ma sorprendentemente capace e ottimizzato per l’esecuzione su dispositivi di fascia media.
Gemma (Google): Un nuovo modello open-source di Google, progettato per essere efficiente e facile da utilizzare.
Dai nostri test quello più equilibrato per potenza e capacità è Gemma 3 12b che offre ottimi risultati in tempi decenti. Ricordati che ogni modello ha i propri vantaggi (quello che ragiona di più, quello che comprende le immagini e via dicendo..)
Installazione con Ollama
Ollama è un framework open-source che semplifica notevolmente il processo di download ed esecuzione di modelli AI sul tuo computer. Rimuove gran parte della complessità tecnica, rendendo l’IA locale accessibile anche a utenti meno esperti.
1. Requisiti Hardware:
Sistema Operativo: macOS (13+) o Linux (64-bit) o Windows 10.
RAM: Almeno 8GB, 32 GB consigliati per un uso decente.
Spazio su Disco: Almeno 10GB, a seconda del modello che vuoi scaricare.
Processore: Un processore moderno con supporto per istruzioni AVX2.
2. Installazione di Ollama:
Il processo di installazione varia leggermente a seconda del tuo sistema operativo:
!– /wp:list-item –>
macOS: Apri l’app “Terminal” e incolla questo comando, poi premi Invio:
curl -fsSL https://ollama.com/install.sh | sh
Questo script scaricherà e installerà Ollama automaticamente.
Linux: Apri l’app “Terminal” e usa il comando appropriato per la tua distribuzione:
Debian/Ubuntu: curl -fsSL https://ollama.com/install.sh | sh
Una volta che Ollama è installato, scaricare un modello è semplicissimo. Prendiamo d’esempio gemma 3 (la lista completa con rispettivi comandi la trovate qua). Apri il Terminale e usa questo comando:
ollama pull gemma:3.4b
Questo comando scaricherà il modello Gemma 3.4b. La dimensione del modello è di circa 3,3GB, quindi il download potrebbe richiedere del tempo a seconda della velocità della tua connessione internet.
4. Esecuzione del Modello Gemma 3.4b:
Dopo che il download è completato, puoi eseguire il modello con questo comando:
ollama run gemma:3.4b
Questo avvierà una sessione interattiva con il modello Gemma. Puoi digitare le tue richieste e il modello genererà delle risposte.
5. Interagire con il Modello:
Dopo aver eseguito il comando ollama run gemma:3.4b, vedrai un prompt di input nel terminale. Puoi digitare le tue domande o istruzioni e premere Invio. Il modello genererà una risposta. Per terminare la sessione, digita /bye e premi Invio.
Tutti i passaggi sopra elencati sono ora semplificati con la nuova applicazione di Ollama appena lanciata
Conclusioni
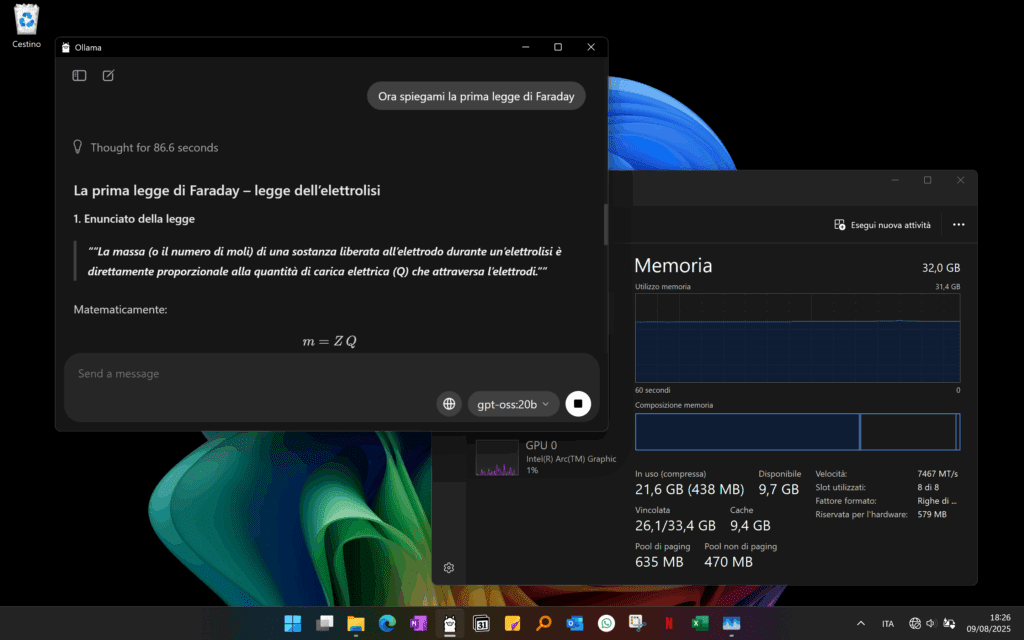
In conclusione è fondamentale cambiare la nostra prospettiva sull’utilizzo dell’IA in locale. Dimentichiamoci la velocità istantanea a cui siamo abituati con i servizi cloud. L’elaborazione di una risposta può richiedere da qualche minuto a decine di minuti, una differenza sostanziale.
Ma questa attesa è il prezzo da pagare per la sicurezza: ogni interazione, ogni dato, rimane confinato nel tuo computer, garantendoti una privacy assoluta. Questa nuova ottica contribuisce anche a ridurre il carico sui giganteschi data center sparsi per il mondo, in particolare negli Stati Uniti, promuovendo una distribuzione più equa delle risorse computazionali e riducendo il loro impatto ambientale.
Perché è importante ricordarsi che se un prodotto è gratis allora il prodotto sei tu.